MongoDB Pro Hint --- Use ObjectID as Timestamp
Did you know MongoDB's ObjectID is actually a timestamp?
The way that it is created is by getting the timestamp at the creation time of the document, a unique machine indicator, and a random number. The combination of those parts produces a 12-byte sequence, 24 hexadecimal chars (e.g: "62bdb3978381b52a31ea0a07").
When a new collection is created, MongoDB creates a default index on _id field.
By utilizing this fact, one can easily query a large DB collection without any relevant indexes, or indexes at all, relatively efficiently.
For example, you have a collection myCollection, which contains 100M documents. Not indexes at all, or non that are relevant to what you search.
If you write your query as:
db.myCollection.find({ myField: { $lt: 10 } });
Not having relevant indexes will force the DB to perform Full Collection Scan (COLLSCAN) and will result in a slow-running query.
By performing this small adjustment you'll cause the DB to utilize the default index of _id and cut the working set, so any of your non-indexed fields will cause smaller set to search within:
db.myCollection.find({ _id: { $gt: ObjectID("62bdb3978381b52a31ea0a07") }, myField: { $lt: 10 } });
Or:
db.myCollection.find({ _id: { $gte: ObjectID("62bdb13b0000000000000000") , $lt: ObjectID("62bc5fbb0000000000000000") , }, myField: { $lt: 10 } });
This will cut the dataset for 1d timeframe and then perform the rest of the non-indexed document search.
Notice that the ObjectIDs are with zeros, this is as we only care about the timestamp portion of the ObjectID and not about the other parts. And timestamp as essentially a number value, is sequential and able to be sorted by.
Obviously, this is only applicable when you have a known time frame.
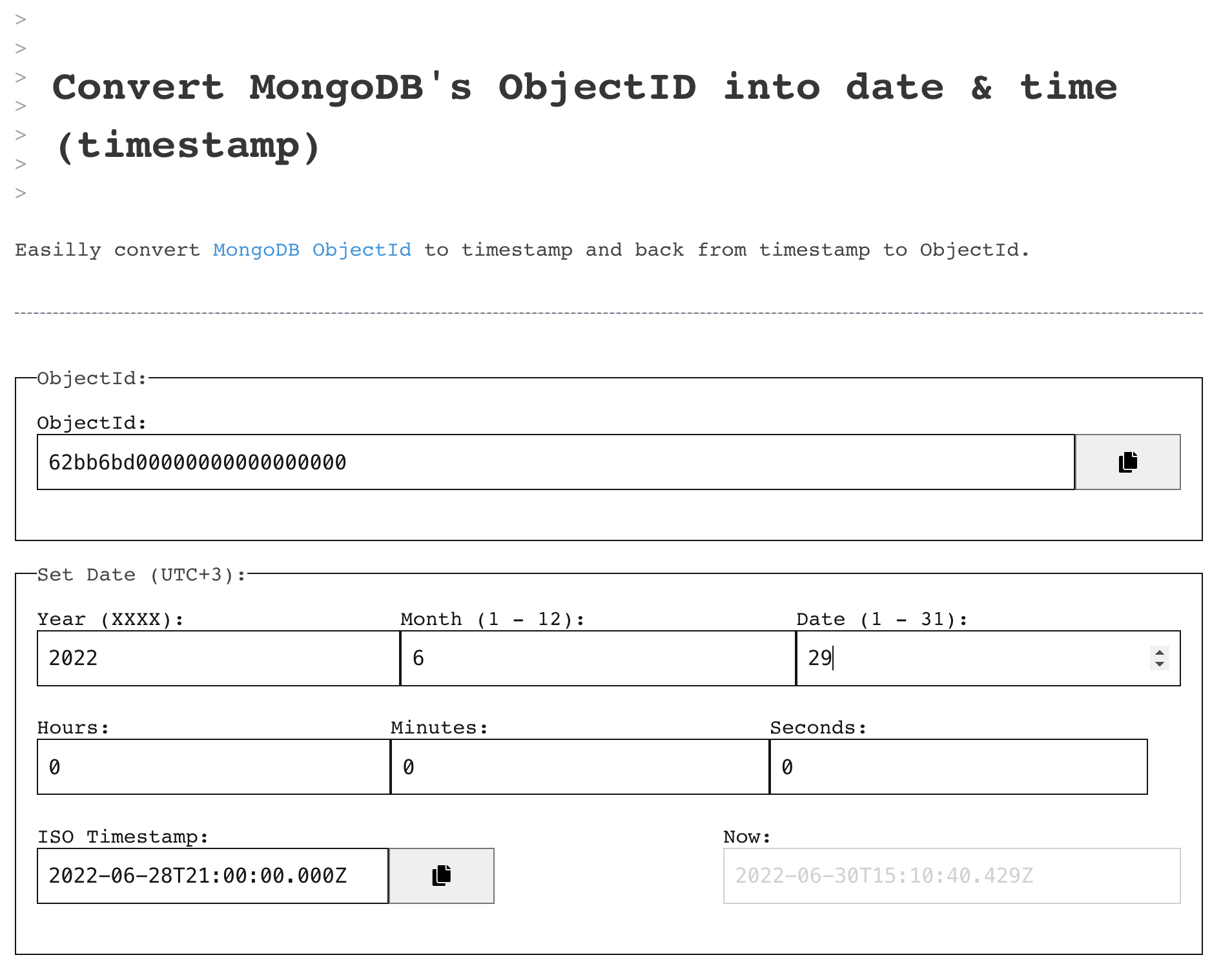
Here's a small utility to easily create and parse ObjectIDs to Timestamp and vice versa:
https://liv.tools/utilities/objectId/62bdb3978381b52a31ea0a07